
マルチモーダルRAGを作ってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
RAG (Retrieval-Augmented Generation; 検索拡張生成) は、大規模言語モデル (LLM) に対して外部知識を与えることで、より正確な回答を生成する手法です。
一般的なRAGはテキストベースの情報検索に焦点を当てていますが、現実世界の情報は文字だけでなく、画像やグラフ、図表など、視覚的な要素も多く含んでいます。
テキストデータに加えて画像や音声などのモダリティを検索対象として含めることで、より広範な情報を検索し、回答を生成できるように拡張したRAGがマルチモーダルRAGです。
本記事では、テキストと画像を扱えるマルチモーダルRAGシステムの実装方法について説明します。
実装したマルチモーダルRAGを実際に動作させた様子を以下の動画で確認できます。
また、今回実装したソースコードは以下のGitHubリポジトリで公開しているので、興味がある方はご覧ください。
そもそもRAGとは?
マルチモーダルRAGについて説明する前に、RAGについておさらいしておきましょう。
RAG (Retrieval-Augmented Generation; 検索拡張生成) は、大規模言語モデル (LLM) の知識を外部データで拡張する手法です。
LLM単体でも広範な知識を持っているため、ある程度の質問には回答できますが、その知識は学習データの範囲と時点に制限されています。
そのため、LLMが学習していない最新の情報や社内独自の情報などについては、正しく回答することができません。
RAGを使用することで、質問内容に基づく情報を取得し、それをLLMに渡すことで、より正確な回答を生成することができます。
また、データの更新が容易であり、LLMの再学習なしで最新の情報を提供できる点もRAGの大きな利点です。
RAGは以下の2つのフェーズから構成されます。
- データ準備フェーズ: データソースから情報を取り込み、インデックスを作成し、検索可能な状態にする。これは通常バッチ処理で行われる。
- 実行時フェーズ: ユーザーのクエリを受け取り、インデックスからデータを検索し、それに基づいて回答を生成する。
各フェーズの処理の流れを以降のセクションで説明します。
データ準備フェーズの処理の流れ
データ準備フェーズの処理の流れを以下に示します。
図中の各コンポーネントの役割は以下の通りです。
- Loader: データソースからデータを読み込む。
- Preprocessor: データを後続の処理で扱いやすい形に変換する。例えば、データをチャンク分割したり、埋め込みベクトルを生成したりする。
- Data Store: 前処理されたデータを保存し、検索可能な状態にする。Pinecone・ChromaDBなどのベクトルDBや、Kendra・OpenSearchなどの全文検索エンジンを使用することができる。
実行時フェーズの処理の流れ
実行時フェーズの処理の流れを以下に示します。
図中の各コンポーネントの役割は以下の通りです。
- Retriever: ユーザーからの質問に基づいて、Data Storeから関連するデータを検索します。
- Generator: ユーザーの質問と検索されたデータを含むプロンプトを受け取り、回答を生成します。回答の生成にはLLMを使用します。
マルチモーダルRAGの概要
マルチモーダルRAGは、テキストデータに加えてその他のモダリティ(画像、音声、動画など)も検索と生成のプロセスに組み込むRAGシステムです。
一般的なRAGはテキストベースの情報検索に焦点を当てているため、テキスト以外の情報に基づいた検索や回答生成が行えません。
現実世界の情報は文字だけでなく、画像やグラフ、図表など、視覚的な要素も多く含んでいるため、それらに基づいた検索や回答生成が行えないのは不便です。
マルチモーダルRAGでは、テキストデータに加えて画像や音声などのモダリティを検索対象として含めることで、より広範な情報を検索し、回答を生成することができます。
本記事では、テキストと画像の2つのモダリティを組み合わせたマルチモーダルRAGの実装方法について説明します。
マルチモーダルRAGのアプローチ
マルチモーダルなRAGを実現するには、検索時に各モダリティのデータを取得し、それらに基づいて回答を生成する必要があります。
複数のモダリティにまたがる検索を実現するアプローチとして、以下のようなものが考えられます[1]。
- すべてのモダリティを同じベクトル空間に埋め込む
- モダリティごとに異なるストアを用意する
- すべてのモダリティを1つの主要なモダリティにまとめる
各アプローチの概要について、以降のセクションで説明します。
すべてのモダリティを同じベクトル空間に埋め込む
このアプローチでは、マルチモーダル埋め込みモデルを使用して、テキストと画像の両方を同じベクトル空間でエンコードします。
これにより、テキストのみに対応するRAGシステムの大部分を流用し、埋め込みモデルを入れ替えて他のモダリティに対応させることができます。
マルチモーダル埋め込みの作成には、Amazon Titan Multimodal Embeddings G1 モデルや Azure AI Vision マルチモーダル埋め込み API、Vertex AI Multimodal Embeddings API などが利用できます。
利点:
- データ準備フェーズの処理内容・インフラ構成がシンプル
- 既存のテキストベースRAGシステムの多くを流用できる
課題:
- 効果的な埋め込みモデルの選定が難しい
- マルチモーダル埋め込みモデルの最大入力トークン数はテキスト埋め込みモデルより少ない傾向にある
- 複雑な画像情報(画像内のテキストや表など)の取り込みがどれほどの精度で行えるか
モダリティごとに異なるストアを用意する
データ準備フェーズの処理の流れ:
実行時フェーズの処理の流れ:
このアプローチでは、異なるモダリティごとに別々のデータストアを用意し、それぞれに対して検索を行います。
その後、専用のマルチモーダルリランカーを使用して、最も関連性の高い情報を選択します。
利点:
- モデリングプロセスがシンプルになり、複数のモダリティを扱うために1つのモデルを用意する必要がない
- 各モダリティに特化した処理が可能
課題:
- 複数のモダリティからの結果を統合するリランカーを用意する必要がある
すべてのモダリティを1つの主要なモダリティにまとめる
このアプローチでは、アプリケーションの主要な焦点に基づいて1つのモダリティ(例: テキスト)を選択し、他のすべてのモダリティをそれに変換します。
例えば、画像に対しては前処理段階でテキストによる説明とメタデータを生成しておきます。
それに加えて、後で参照するために画像の元データを保存しておきます。
利点:
- 情報豊富な画像から生成されたメタデータが客観的な質問への回答に有効
- マルチモーダル埋め込みベクトルモデルのチューニングや選定が不要
- 異なるモダリティ間の検索結果をリランクする必要がない
課題:
- 前処理のコストが高い
- 画像のニュアンスの一部が失われる可能性がある
今回採用したマルチモーダルRAGの処理概要
先述したマルチモーダルRAGのアプローチの中から、今回は「すべてのモダリティを1つの主要なモダリティにまとめる」アプローチを採用しました。
実装には、LangChainライブラリが提供する MultiVectorRetriever を利用します。
これを利用することで、テキストと画像の説明を紐付けて管理し、検索することができます。
データ準備フェーズ
マルチモーダルRAGのデータ準備フェーズの処理概要を以下に示します。
画像に対しては画像の説明文を生成する処理が行われます。
この説明文に対する埋め込みベクトルを生成し、MultiVectorRetrieverに格納します。
MultiVectorRetrieverは、内部的にベクトルDBとDocstoreを管理しています。
ベクトルDBではテキストと画像の説明文の埋め込みベクトルを、Docstoreでは元の画像データとテキストデータを保持します。
ベクトルDBとDocstoreに保持されたデータは紐付けて管理されており、検索時にはベクトルDBに対して検索クエリに関連するベクトルを検索し、それに紐付く元データをDocstoreから取得します。
実行時フェーズ
マルチモーダルRAGの実行時フェーズの処理概要を以下に示します。
MultiVectorRetrieverに対して検索を行うと、画像に関しては検索クエリと画像の説明文の類似度に基づいた検索が行われ、検索結果として画像の説明文と元の画像データが取得されます。
テキストに関しては、通常のRAGと同様に検索クエリに関連するテキストが取得されます。
これらの検索結果およびユーザーの質問がGeneratorに渡され、回答が生成されてユーザーに返されます。
システム構成概要
今回構築したシステム構成の概要を以下に示します。
RAGのインターフェースにはSlackを利用し、Slackボットに対して質問をメンションすると回答を返信してくれるようにしました。
インフラは次のとおり、主にAWSを利用しています。
- コンピューティング: Lambda
- MultiVectorRetrieverのDocstore: S3
- MultiVectorRetrieverのベクトルDB: Pinecone
- LLM基盤: Bedrock
Slack Botの実装にはSlack Boltを利用し、RAGの実装にはLangChainを利用しました。
Slack BoltとLangChainを用いたRAGの実装については、以下の記事で紹介しています。
データ準備の実行は、開発者がローカルマシンからスクリプトを実行する構成にしています。
実装のポイント
先述したとおり、今回実装したソースコードは以下のGitHubリポジトリで公開しています。
このソースコードに関して、重要なポイントをピックアップして説明します。
データの前処理
データの前処理は、DocumentPreprocessorクラスを使用して行います。
このクラスは、ウェブページからのデータを取得し、Markdown形式に変換し、画像の説明を生成します。
以下は、DocumentPreprocessorクラスの主要なメソッドです。
class DocumentPreprocessor:
# 略...
def preprocess(self) -> list[Document]:
# 略...
image_docs = self._extract_image_descriptions(markdown_docs)
# 略...
def _extract_image_descriptions(
self, docs: Sequence[Document]
) -> list[MetadataTypedDocument[ImageMetadata]]:
# 略...
preprocessメソッドでは、まずウェブページからHTMLドキュメントを取得し、Markdown形式に変換します。その後、_extract_image_descriptionsメソッドを呼び出して、画像の説明を生成します。_extract_image_descriptionsメソッドでは、ExtractImageConvertorを使用して画像を抽出し、describe_images関数を呼び出して画像の説明文を生成します。
このプロセスにより、テキストと画像の両方の情報が統合され、後続の処理で使用できるようになります。
画像の説明文生成
画像の説明文生成には、describe_images関数を使用します。
LangChainのチェーンとして、与えた画像について説明を行う処理を定義し、これを実行することで画像の説明文を生成しています。
今回はLLMとしてBedrock経由でClaude 3 Haikuを使用しています。
また、画像の説明文を生成するためのプロンプトには、以下のようにシンプルなものを使用しています。
Describe the image in detail in Japanese.
データのインデックス化
前処理したデータに対する埋め込みベクトルの生成および、それらのデータを検索可能な状態にインデックス化する処理はDocumentIndexerクラスで行います。
先述したとおり、埋め込みベクトルと元データを紐付けて管理するために、MultiVectorRetrieverを使用します。
MultiVectorRetrieverは、内部的にベクトルDBとDocstoreを管理しており、それぞれで以下のデータを保持します。
- ベクトルDB: 埋め込みベクトル
- Docstore: 元データ
ベクトルDBとDocstoreに保存されたデータには識別子として doc_id が付与されており、これによってそれぞれのデータを紐付けることができます。
今回は以下の構成で、MultiVectorRetrieverを構築しています。
- ベクトルDB: Pinecone
- Docstore: S3
- 埋め込みモデル: Amazon Titan Text Embeddings v2
検索と回答生成
実行時フェーズにおける検索と回答生成の処理はRagクラスで実装されています。
このクラスの処理概要は以下のとおりです。
- ユーザーの質問を受け取り、それに関連するテキストと画像を検索する
- 検索結果とユーザーの質問をもとにプロンプトを成形する
- LLMにプロンプトを与え、回答を生成する
今回はLLMとしてBedrock経由でClaude 3 Haikuを使用しています。
プロンプトに関しては、LangChain Hub で公開されている rlm/rag-prompt というプロンプトを参考に、以下のようにシンプルなものを使用しています。
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
また、LLMの回答はCitedAnswerというデータ構造に則った形式で返すようにしています。
これにより、生成された回答をSlackメッセージとしてフォーマットしやすくなります。
特定のデータ構造に則った回答を生成するために、with_structured_outputメソッドを使用しています。
with_structured_outputメソッドについては、以下の公式ドキュメントで詳しく解説されています。
動かしてみる
今回は、以下のWebページをクローリングした内容について回答できるようにデータを準備しました。
冒頭にも示したとおり、今回作成したマルチモーダルRAGに対して実際に質問してみたところ、以下のように回答が生成されました。
問い合わせ対応自動化のフローについて質問してみたのですが、以下の画像に基づいた回答を返してくれています。
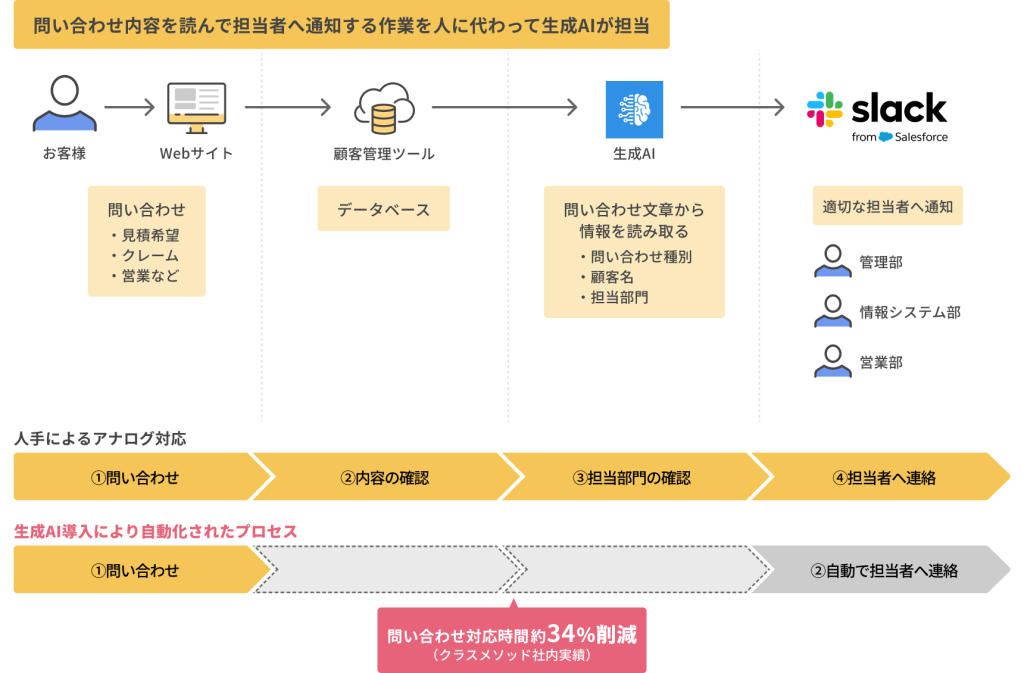
今後の展望
今回はテキストと画像の2つのモダリティを扱え、それらの情報に基づいて最低限回答が行えるRAGを構築しました。
今後の展望としては、以下のような拡張が考えられます。
- 各種チューニング
- 画像の説明文生成のプロンプトの改善
- 回答生成のプロンプトの改善
- Advanced RAG による精度改善
- 動画や音声など他のモダリティへの対応
- データ準備フェーズを定期的に実行することで、データの更新を継続的に行う仕組みの構築
- ユーザーフィードバックを活用した継続的な学習システムの導入
おわりに
今回はテキストと画像の2つのモダリティの情報に基づいて回答を生成するRAGを構築しました。
テキスト以外のモダリティにも対応することで、より広範な情報を検索し、より詳細な回答が生成できるようになることが期待できます。
本記事で紹介した実装方法を基に、各自のユースケースに合わせたカスタマイズを行うことで、より便利なアプリケーションの開発が可能になるでしょう。
以上、どなたかの参考になれば幸いです。
参考情報
- Build a Retrieval Augmented Generation (RAG) App | 🦜️🔗 LangChain
- 【RAG】画像・テーブルデータに対応可能な Multi-representation-indexing について | Hakky Handbook
- Multi-Vector Retriever for RAG on tables, text, and images
- generative-ai/gemini/use-cases/retrieval-augmented-generation/multimodal_rag_langchain.ipynb at main · GoogleCloudPlatform/generative-ai
- RAGの課題と精度改善のための発展的なアプローチまとめ | Hakky Handbook









